Data Lake Reference Architecture
Data lake is a single platform which is made up of, a combination of data governance, analytics and storage. It’s a secure, durable and centralized cloud-based storage platform that lets you to ingest and store, structured and unstructured data. It also allows us to make necessary transformations on the raw data assets as needed. A comprehensive portfolio of data exploration, reporting, analytics, machine learning, and visualization on the data can be done by utilizing this data lake architecture.
DATA LAKE VS DATA WAREHOUSE
While a data warehouse can also be a large collection of data, it is highly organized and structured. In a data warehouse, data doesn’t arrive in its original form, but is instead transformed and loaded into the organization predefined in the warehouse. This highly structured approach means that a data warehouse is often highly tuned to solve a specific set of problems, but is unusable for others. The structure and organization make it easy to query for specific problems, but practically impossible for others.
A data lake on the other hand, can be applied to a large number and wide variety of problems. Believe it or not, this is because of the lack of structure and organization in a data lake. The lack of a predefined schema gives the data lake more versatility and flexibility. A Data Lake operates, with a more broad and distributed context, where some questions remain ambiguous, with an undefined set of users and a variety of different data presentations. One of the core capabilities of a data lake architecture is the ability to quickly and easily ingest multiple types of data, such as real-time streaming data and bulk data assets from on-premises storage platforms, as well as data generated and processed by legacy on-premises platforms, such as mainframes and data warehouses.
WHY DO WE NEED A DATA LAKE?
Managed Unlimited Data
A Data Lake can store unlimited data, in its original formats and fidelity, for as long as you need. As a data staging area, it can not only prepare data quickly and cost effectively for use in downstream systems, but also serves as an automatic compliance archive to satisfy internal and external regulatory demands. Unlike traditional archival storage solutions, a Data Lake is an online system: all data is available for query.
Accelerate Data Preparation and Reduce Costs
Increasingly, data processing workloads that previously had to run on expensive systems can migrate to a Data Lake, where they run at very low cost, in parallel, much faster than before. Optimizing the placement of these workloads and the data on which they operate frees capacity on high-end data warehouses, making them more valuable by allowing them to concentrate on the business-critical OLAP and other applications for which they were designed.
Explore and Analyze
Fast Above all else, a Data Lake enables analytic agility. IT can provide analysts and data scientists with a self-service environment to ask new questions and rapidly integrate, combine, and explore any data they need. Structure can be applied incrementally, at the right time, rather than necessarily up front. Not limited to standard SQL, a Data Lake offers options for full-text search, machine learning, scripting, and connectivity to existing business intelligence, data discovery, and analytic platforms. A Data Lake finally makes it cost-effective to run data-driven experiments and analysis over unlimited data.
GENERAL DATA LAKE REFERENCE ARCHITECTURE
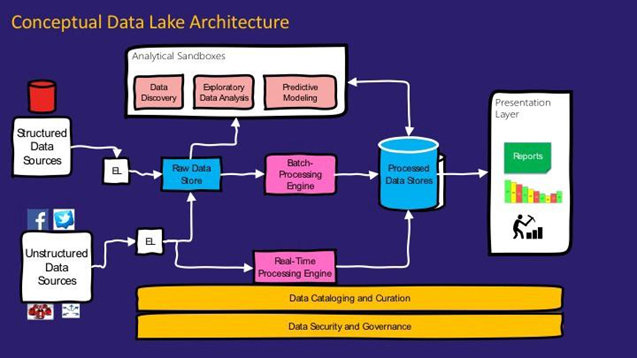
Ref: www.datasciencecentral.com/profiles/blogs/demystifying-data-lake-architecture
Here are the key components in a data lake architecture. We have our data sources which can be structured and unstructured. They all integrate into a raw data store that consumes data in the purest possible form without any transformations. It is a cheap persistent storage that can store data at scale.
Analytical sandboxes are one of the key components in data lake architecture. These are the exploratory areas for data scientists where they can develop and test new hypothesis, mash-up and explore data to form new use-cases, create rapid prototypes to validate these use-cases and realize what can be done to extract value out of the business.
Then we have batch processing engine that processes the raw data into something that can be consumed by the users. In other words, a structure that can be used for reporting to the end users. Then the transformed data would be stored in processed data store. There is a real-time processing engine that takes streaming data and processes it as well.
Finally once the necessary data is being stored, the BI tools would be able to leverage those to show meaningful graphs and numbers to the end customers. For example sales per quarter, growth within a region for the year etc.
AWS DATA LAKE REFERENCE ARCHITECTURE
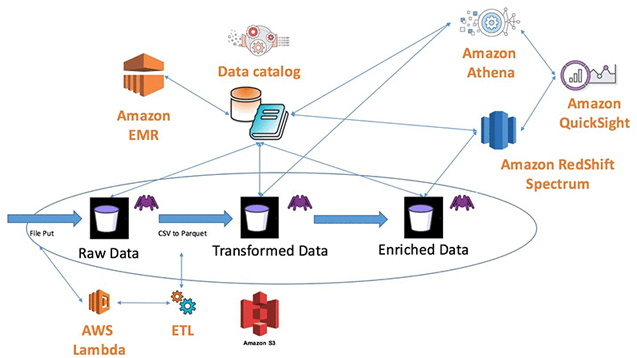
Ref: www.aws.amazon.com/blogs/big-data/build-a-data-lake-foundation-with-aws-glue-and-amazon-s3
The aws data lake foundation provides these features:
Data Lake Reference Architecture - Case Study 01
Auxenta was engaged with a manufacturing organization in the USA. Their requirement was to build a data lake solution in order to visualize some sales related KPIs’ in a dashboard.
In order to make this requirement a success, the team took the initiative to adopt the data lake architecture which has been explained briefly in the above sections. There were couple of other tools which were being used within the architecture such as Matillion and Tableau.
Initially the raw data is being stored in s3 buckets from various input sources on a daily basis. Whenever a file comes into the S3 bucket, the lambda function which is attached to that bucket, would get triggered and will send out a message to SQS. Once SQS receives the message, it will send the information (contains the job information) which was received from the lambda function, to the Matillion (An ETL tool) instance. The Matillion instance would be listening to the SQS queue, and once it receives the message from SQS, it would trigger the appropriate job in Matillion. The jobs which are available in Matillion are, four different orchestration jobs in order to pull in data from the S3 buckets into the Redshift tables and a transformation job which consists the join function which inserts the data into the fact table.
Then data will be pushed into Redshift data warehouse, as into staging tables. Then the raw data from the staging tables are extracted, and will be transformed before it gets inserted into the fact table. In order to do the transformation, Matillion is being used. Once the transformations are done, the transformed data will be inserted into the fact table based on some joins from other dimension tables.
The data in the fact table is being backed up into a S3 bucket every day on a schedule basis. After the data is being loaded into the fact table, Tableau can connect to the Redshift endpoint and access the schema and the tables. Tableau is being used as the visualization tool, in order to create calculated fields and graphs based on the required KPIs’ which would ideally help the business related employees to witness a high-level look on the ups and downs of their organization.

Kulasangar Gowrisangar
AuthorDeveloping a Custom Audit Trail and a Notification Service for a Workflow Based Serverless Application on AWS
READ ARTICLE
Human Emotions Recognition through Facial Expressions and Sentiment Analysis for Emotionally Aware Deep Learning Models
READ ARTICLE