Human Emotions Recognition through Facial Expressions and Sentiment Analysis for Emotionally Aware Deep Learning Models
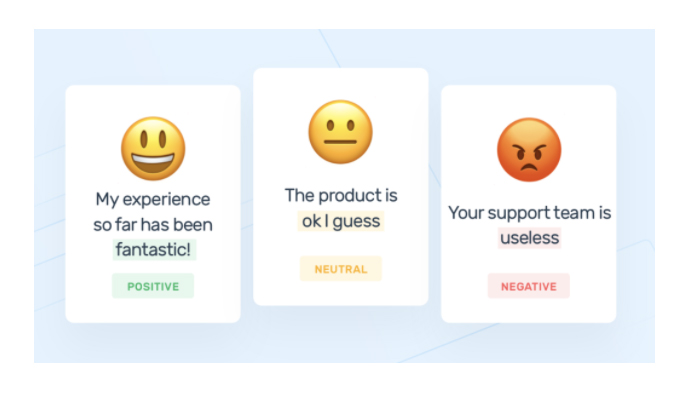
Emotions often mediate and facilitate interactions among human beings. Thus, understanding emotion often brings context to seemingly bizarre and/or complex social communication. Emotion recognition can be identified through various methods such as voice intonations and body language, and also with more complex means like electroencephalography. Still, the most viable and simple method is to observe facial expressions. The seven basic human emotions are happiness, fear, outrage, sadness, surprise, disdain and loathing. These are common for any social or cultural group across the world. When considering these facts, it is visible that human emotions have a huge impact on actions and reactions to situations.
Recognition of emotions is important in providing proper responses to users when developing AI models like Emotionally Aware Deep Learning Models. Importance of providing responses according to users emotions is described through the below image simply.
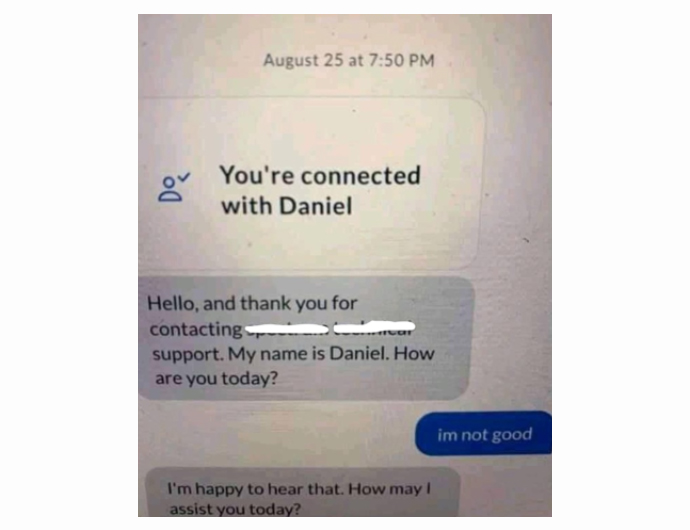
In this article two methods of recognising emotions (Sentiment Analysis and Human Facial Expression Recognition) is discussed.
Sentiment Analysis
Sentiment analysis is a sub field of Natural Language Processing (NLP) which attempts to extract subjective opinions of a given text. Sentiment analysis spans across recognising emotions, intent and sarcasm of a text. Simply put, this assigns polarity to a given text. As an example, “M&M is one of the worst ice creams I’ve ever tried”, contains negative polarity. The sentiment phrase is “worst ice cream” and directed at sentiment target “M&M”. “Snickers and Mars will release their newest chocolate flavours tomorrow”, this is a factual sentence about Snickers and Mars therefore it contains a neutral context. “Snickers ice cream became the most popular and fast selling ice cream in the past year”, has a positive opinion since it has words like “most popular” and “fast selling” in reference to Snickers.
Challenges of Sentiment Analysis
Human language contains certain subtleties which are traditionally associated with the language and it’s a challenging task to extract accurate sentiment of a certain phrase.
Negation handling: — Ex: — “How’s your office work? Not Too bad! I’m not super happy with the latest salary raise though…” While the first sentence contains neutral polarity, the second sentence contains a positive opinion, but at the same time has “too bad” which originally is a negative phrase. The third sentence has a negative context but contains “super happy” which originally has a positive opinion.
Sarcasm: — Ex: — “That’s just what I needed today...Great!”. Regardless of the expression “great”, the sentence is probably being sarcastic and contains a negative polarity.
Comparisons: — Ex: — “I love the new Snickers ice cream, it is so much better than M&M”. Though “love” and “much better” carry out a positive polarity, it is not a good statement in M&M’s point of view.
In all of the above examples, you need to understand the meaning of the full context along with the meaning of the words. Trading off between accuracy and speed is one practical challenge that has to be faced when using sentiment analysis algorithms. Naive Bayes, Support Vector Machines and Logistics Regression are some traditional machine learning (ML) techniques that are widely used for large scale sentiment analysis, since they scale very well. It is proven that Deep Learning (DL) strategies can achieve higher level of accuracy in various NLP tasks like sentiment analysis, but they are more expensive to train and are typically slower.
Lack of availability of manually annotated data has caused limitations to NLP tasks. Lately, Twitter has gained high popularity as a microblogging platform across the world. Several organisations have data mining researches being conducted, by using tweets which are collected from Tweepy API.
Approach of Sentiment Analysis
Rule based systems and machine learning systems are the two main approaches of sentiment analysis.
Rule Based Systems
In rule based systems there is a pre-defined data set of polarized terms and expressions that represent a particular opinion. As an example, this pre-defined data set can contain a list of positive words such as “happy”, “fun”, “good”, “beautiful” and a list of negative words such as “sad”, “bad”, “worst”. Then for a given phrase the number of positive terms and negative terms are counted. Rule based systems define the final polarity of the sentence depending on this count. If the sentence contains a higher number of terms from the positive list, it is recognised as a positive opinion and vice-versa.
Machine Learning Systems
In machine learning systems, it is essential to have a training dataset. This dataset contains examples with different expressions such as positive, negative, neutral, etc. ML algorithms are used for this technique. Example phrases are transferred into vectors since ML algorithms don’t understand text directly. Next, these vectors are used to train models with algorithms like Naive Bayes and Support Vector Machine (SVM). Then the trained model is used to predict the sentiment of a new sentence by transforming the text into vectors and feeding it to the classifier. This will return labels containing expressions for that particular sentence.
Stages of ML System Sentiment Analysis
Using Twitter datasets as training datasets has its advantages like scalability, real-time analysis and consistent criteria. The below figure contains the flow chart of the training and predicting of sentiments.
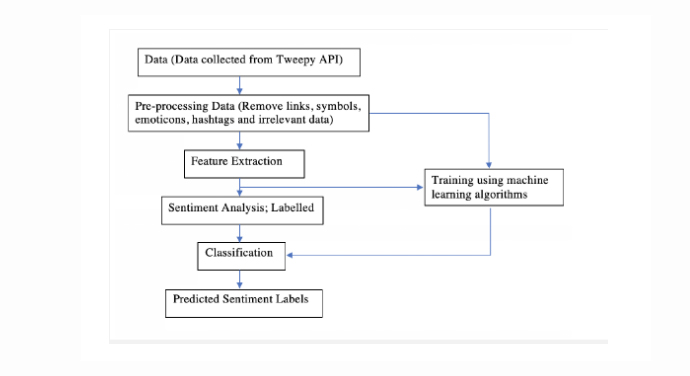
Data Gathering
A Twitter dataset can be used to train the ML model and to run the actual sentiment analysis on test data. There are two main types of Twitter data - current tweets and historical tweets. Current tweets help to track the latest keywords and hashtags. This helps to keep the model updated with real-time data. While historical data helps to train the model with a large number of phrases. Extracting data from Twitter can be done using APIs like Twitter API, Tweepy API and tools like Zapier, IFTTT, Export Tweet, Tweet Download, etc.
Data Pre-Processing
Reliability of the result of sentiment analysis depends mainly on the quality of data. Therefore, it is critical to have cleaned data. In the pre-processing phase, irrelevant information like symbols, emojis, hashtags, extra blank spaces, special characters are removed. Pre-processing also includes, removing tweets which have less than three characters and removing duplicate tweets.
Feature Extraction
In the feature extraction phase, texts are transformed into vectors. This is done by using vectors for dimensions representing frequencies for a given text.
ML Approach
Machine learning classification consists of two main groupings which are, supervised learning and unsupervised learning. The labelled dataset is fed to the model and trained in supervised learning whereas, unsupervised learning does not have any targets or categories provided at all. Few of the classifiers used in ML approach are described below.
(a) Naive Bayes Classifier
The Naive Bayes classifier uses a considerable amount of features which are used in feature vectors. These features are independent. Naive Bayes conditional probability mathematical representation is as below.
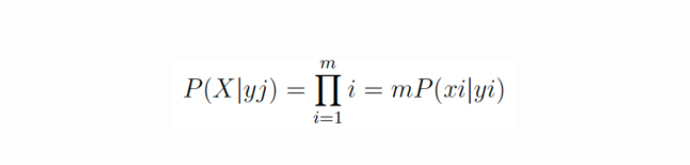
“X” represents the feature vector which is denoted by X=x1, x2,….xm and “yj” represent class labels. Independent feature classification is efficiently classified using Naive Bayes classifier.
(b) SVM Classifier
SVM utilises a huge margin for classification. The below function is used for SVM.
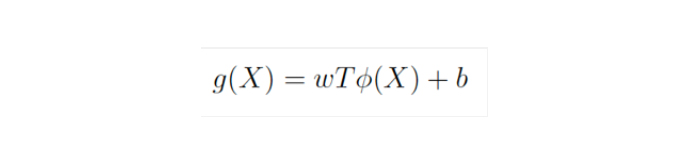
“X” represents the feature vector, “w” represents the weight vector, and “b” represents the bias vector. ⏀denotes non-linear mapping where information space is transferred to high dimensional feature space.
Lexicon Based Approach
The lexicon based approach is representing a chunk of a text message as a bag of words. Sentiment values are tagged for this representation. Functions like average or sum are used to identify the final sentiment. Local context of the message is also taken into consideration while identifying the final sentiment.
Human Facial Expression Recognition
Recognition of emotions of a user can be gathered by analysing physical characteristics such as body movements, voice, face and other biosignals. From these methods, the most viable and effective physical feature to obtain emotions is the face. While humans can understand emotions effortlessly, computers need techniques like Facial Expression Recognition (FER).
Pattern based recognition of NLP is the root of face recognition and emotion recognition. Acquisition, pre-processing, feature extraction and emotion classification are the main stages of FER. The region of the face is recognised from the input image and landmarks like nose, eyes and mouth are detected after detecting a face in an image. Then the features are extracted and classified to discern the sentiment.
Main Stages of FER
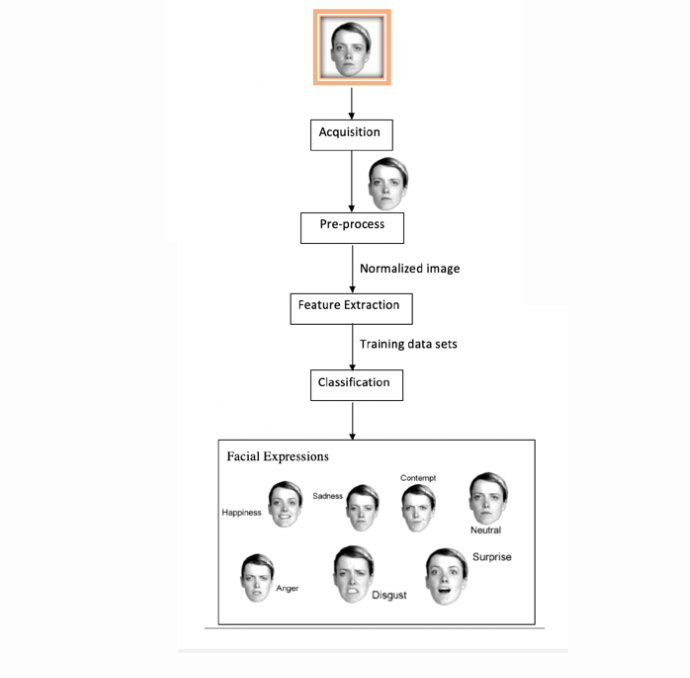
Acquisition
Determination of a human face in an image is done using the process of face localization. Location and the size of the image is also captured by using face localization. In other words, it’s the process of demarcating the area of the face. Assortments of strategies are used for localization according to the use of distinctive features. Face edges are used for complete face demarcation. Additionally, details of the face texture is also used for localization. Skin complexion has unique characteristics and information of the complexion is frequently used for localization since it stands out independently in colour space.
Pre-process
The objective of pre-processing is to enhance the features of the image for the next steps of the process and to suppress unfavourable distortions. The main stages of pre-processing include reading the image, normalization of image size, removing noise (denoise), segmentation, and morphology (smoothing edges).
Extraction
Feature extraction is where key data is captured from the image such as vectors, symbols and values. Feature extraction technique is decided upon depending on the application environment and classification method - Local Binary Pattern (LBP), Gabor feature extraction, Haar-like feature extraction, feature point tracking and optical flow method, etc. Applicability and the feasibility of applying particular methods need to be considered when choosing an appropriate feature extraction method because this may have direct control over the performance of the algorithms which is a bottleneck of FER applications.
Classification
Classification is carried out to identify the facial expression of the image. Selecting an appropriate classifier has significant influence over the accuracy of the emotion captured in FER systems. Support Vector Machine (SVM), Bayesian, k-Nearest Neighbours (kNN), Probabilistic Neural Network (PNN) and Sparse Representation based Classifier (SRC) are some of the widely used classifiers in FER applications. FER approaches are comparatively less dependent on hardware and data when compared to other deep learning methods, but feature extraction and classification cannot be optimised simultaneously. Therefore, it is needed to design them separately. Accuracy of the FER result depends on the performance and accuracy of each stage.
As discussed above, the SA and FER methods can be used to identify the emotions of the user interacting with the system for better response creation in AI models such as Emotionally Aware Deep Learning Models. Yet, these methods come with restrictions and uncertainties. The time for processing is not evaluated and it is very important in FER. Emotions can change drastically and if the FER techniques take a long processing time, the results presented would not be real-time and can be deemed as low accuracy results.
Moreover, SA is only developed for English language and it is important to have SA in other native languages, to conclude that machines are emotionally intelligent. Furthermore, techniques to capture sentiments in multilingual phrases is not yet developed, and these are the research gaps that make the computer-human conversational interaction limited to English language and monolingual.
Shamila Sallay
Senior Software EngineerDeveloping a Custom Audit Trail and a Notification Service for a Workflow Based Serverless Application on AWS
READ ARTICLE
Human Emotions Recognition through Facial Expressions and Sentiment Analysis for Emotionally Aware Deep Learning Models
READ ARTICLE