Building an OCR Backend with AWS Textract – A Case Study
This blog primarily talks about how AWS Textract [1] can be leveraged, along with other AWS services, to extract document/image data into a NOSQL database (DynamoDB) for further processing. Auxenta has used this solution architecture for multiple client engagements in the AWS stack.
The Solution Architecture
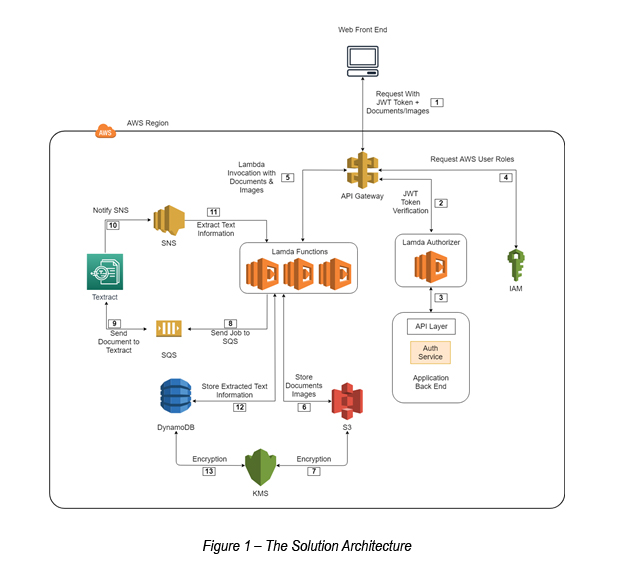
The complete solution architecture can be explained in a few steps.
Step 01- Storing images in S3
All the front-end web/mobile requests run through an AWS API Gateway with a valid JWT token. The AWS API Gateway uses the Lambda Authorizer for the JWT token verification. After a successful token verification, the API gateway will invoke a Lambda function in order to store the received document/image into an S3 bucket. All the documents/images are encrypted using AWS KMS.
Step 02- Text extraction using AWS Textract
As of now, AWS Textract has a limitation of only supporting 2 asynchronous image text extraction processes per account. To overcome this and to make the process more asynchronous and decoupled, AWS SQS has been proposed.
The SQS will trigger a Lambda function for image/document extraction with the help of AWS Textract. Once AWS Textract completes the extraction process, SNS invokes another Lambda function to store the extracted text data in DynamoDB.
[P.Note: A detailed step-by-step guide on how to use AWS Textract with Lambda could be found here.]
Step 03- Handling of high priority images with multiple queues
A particular Auxenta client had a requirement for high priority messaging. Since AWS SQS does not support high priority message processing, the solution architecture had to go through the following change (see Figure 02).
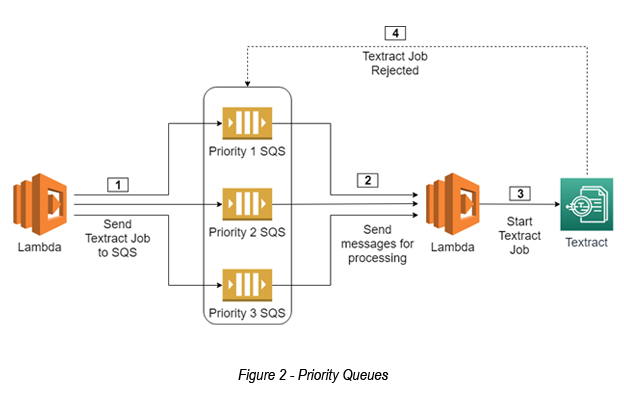
The solution entailed creating multiple SQS instances for each priority level.
Here the Lambda function checks the priority of the request and adds the job to the relevant priority queue. The Lambda function starts text extraction using AWS Textract processing for high priority messages. If Textract rejects the request due to any issue, the messages are put back in the queue for later retrial.
The CI/CD aspect is completely automated with the help of AWS CodePipeline, AWS CodeBuild and Serverless Framework [2].
AWS CodePipeline
AWS CodePipeline will be used to configure the CI/CD pipeline for separate environments such as Dev, Staging, QA and Production.
AWS CodeBuild
AWS CodeBuild will be utilized to provide a build environment in which the Serverless Framework will be executing deployment steps from within.
Serverless Framework
This will provision all the required AWS resources for a given environment (Dev/QA/Production).
Please refer the following CI/CD sequence (see figure 03).
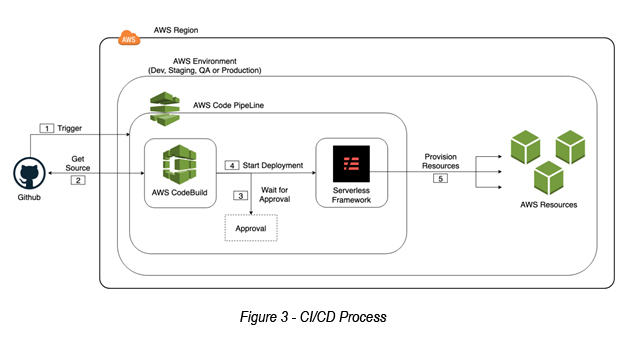
- A developer commits code to project master branch and this triggers the AWS CodePipeline.
- AWS CodeBuild will pull the source code from Github and start the build process.
- [Optional] AWS CodePipeline will send the approval notification and wait.
- AWS CodePipeline will start the Serverless Framework deployment.
- The Serverless Framework starts provisioning AWS resources or updates them.
References
[1] AWS Textract : www.aws.amazon.com/textract
[2] Serverless Framework : www.serverless.com
[3] AWS Textract with Lambda Walkthrough: www.1billiontech.com/blog_aws_textract_with_lambda_walkthrough.php

Suminda De Silva
Associate Technical LeadDeveloping a Custom Audit Trail and a Notification Service for a Workflow Based Serverless Application on AWS
READ ARTICLE
Human Emotions Recognition through Facial Expressions and Sentiment Analysis for Emotionally Aware Deep Learning Models
READ ARTICLE