AWS Disaster Recovery Scenarios
Disaster Recovery (DR) is all about “preparing for” or “recovering from” a disaster [1]. In this blog, I will explain Disaster Recovery scenarios/options that are available on AWS. It is important to have a high level understanding of these options when we are designing fault tolerant, highly available AWS solution architectures.
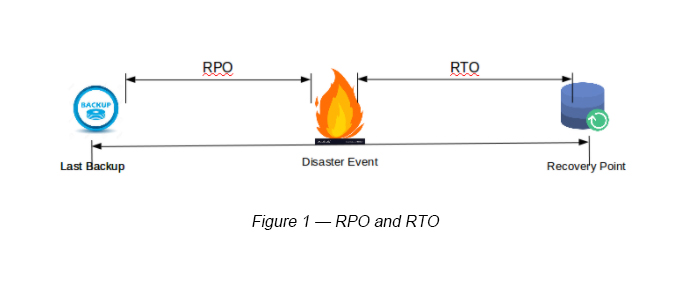
As the first step, let’s try to understand what Recovery Point Objective (RPO) and Recovery Time Objective (RTO) is all about and then dive into DR scenarios on AWS.
RPO vs RTO
RPO and RTO, in essence, are benchmarks that we can define before we set up a DR system for an application that is going to be deployed in the cloud.
If both RPO and RTO have a low figure, that means you have a system that has a near real time DR plan.
Recovery Time Objective (RTO)
This indicates the time it takes to recover from a disaster (restoring a business process to its service level, as defined by the Operational Level Agreement).
For example, if a disaster occurs at 12.00pm (noon) and the RTO is four (04) hours, the DR process should recover the system by 4.00pm.
Recovery Point Objective (RPO)
The acceptable amount of data loss measured in time.
For example, if a disaster occurs at 12:00 PM (noon) and the RPO is one hour, that means the system should recover all its data that was in the system by 11:00 AM. That means, the total data loss is only one hour between 11.00am and 12.00pm (noon).
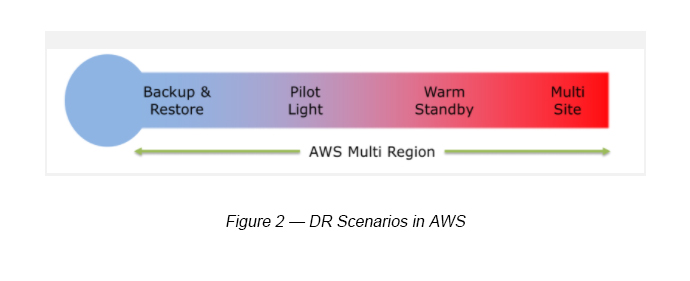
Disaster Recovery Scenarios in AWS
There are basically four (04) Disaster Recovery scenarios identified in AWS (see Figure 2). Among them, some have a higher RTO and some have a lower RTO. It is always good to understand how we can minimize RTO and what level of commitment is needed to achieve those levels.
- Backup and Restore — Data is backed up and restored
- Pilot Light — Only minimal critical functionalities
- Warm Standby — Fully functional scaled down version
- Multi Site (Active-Active) — Another fully functional site
Out of these four scenarios, Multi Site (Active-Active) has the lowest RTO and Backup and Recovery has the highest RTO.
P.Note: In these scenarios, the site where the disaster happens is referred to as “primary infrastructure” and the recovery infrastructure is referred to as “secondary infrastructure”. The “primary infrastructure” could either be an “on-premise” or an “AWS infrastructure”. The “secondary infrastructure” will be an “AWS infrastructure”.
Let’s dive into these four scenarios to some detail.
1.0 Backup and Restore
There are multiple backup options available.
- Amazon S3 — Amazon S3 is an ideal destination for backup data that might be needed to quickly perform a restore.
- Amazon Glacier — Glacier can also be used in conjunction with S3 to produce a tiered “long-term” backup solution.
- Amazon Import/Export — This can be used to transfer very large data sets by shipping storage devices directly to AWS.
- Amazon Storage Gateway — This enables snapshots of your on-premise data volumes to be transparently copied into S3 for backup. Cached volumes allow you to store primary data in S3, but can keep your frequently accessed data locally for low-latency access. VTL configuration can be used as a replacement for traditional magnetic tape backup.
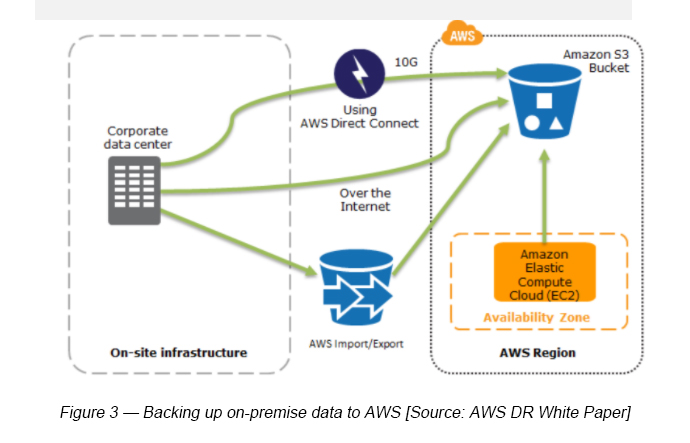
When it comes to restoring data from EC2 instances, this can be done through a combination of the following (see Figure 4).
- Provisioning the instances from an AMI
- Restoring data from S3

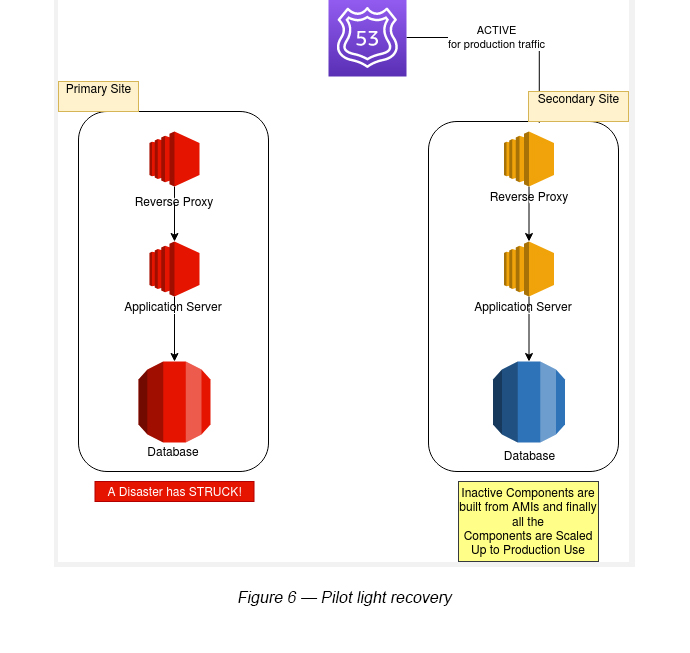
2.0 Pilot Light
The secondary environment that runs only the most critical core infrastructure. When the time comes for recovery, you can rapidly provision a full scale production environment around the critical core.
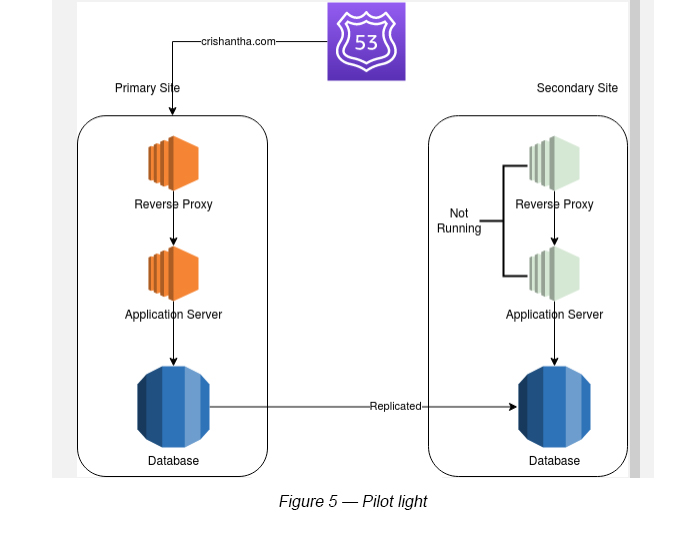
The pilot light method gives you a quicker recovery time than the backup-restore method because the core pieces of the system are already running and are continually kept up to date.
In Figure 5, the database is up and running, but the other components (Reverse Proxy and the Application Server) are inactive.
In order to recover the inactive components and to scale up the running components, you can adhere to one of the following steps:
- Start your EC2 based instances from any customized AMIs
- Scale up database instances, if required
- Add any fail-over features to both inactive and active components (Multi-AZ, etc.)
- Point the Route 53 DNS to the secondary site
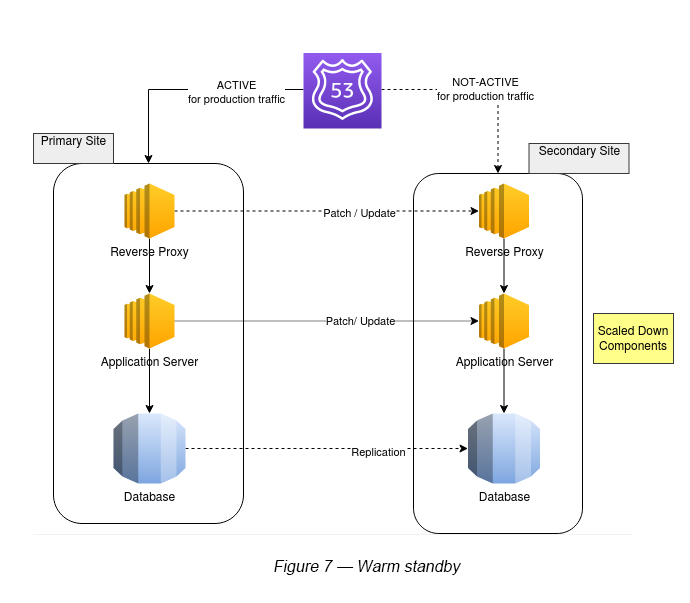
3.0 Warm Standby
This is where the secondary (backup) environment runs the same infrastructure as the primary one, but in smaller sized components to reduce costs (see Figure 7). For example, if the primary infrastructure has an extra large EC2 instance, the secondary site would run a medium sized EC2 instance.
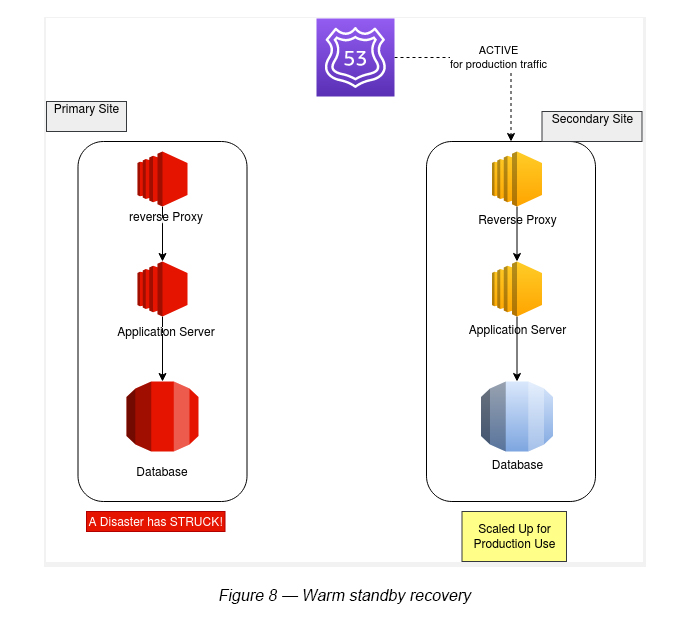
When a disaster occurs, smaller version(s) can be scaled up instantly to provide an infrastructure similar to the primary one in a quicker time than the Pilot light method (see Figure 8).
4.0 Multi Site (Active-Active)
This is where the secondary (backup) infrastructure is a copy (in structure, size and services running) of the primary site.
This allows for the best performance, high availability and the best recovery time compared to other DR scenarios explained. However, the cost will be exactly double of the primary infrastructure.
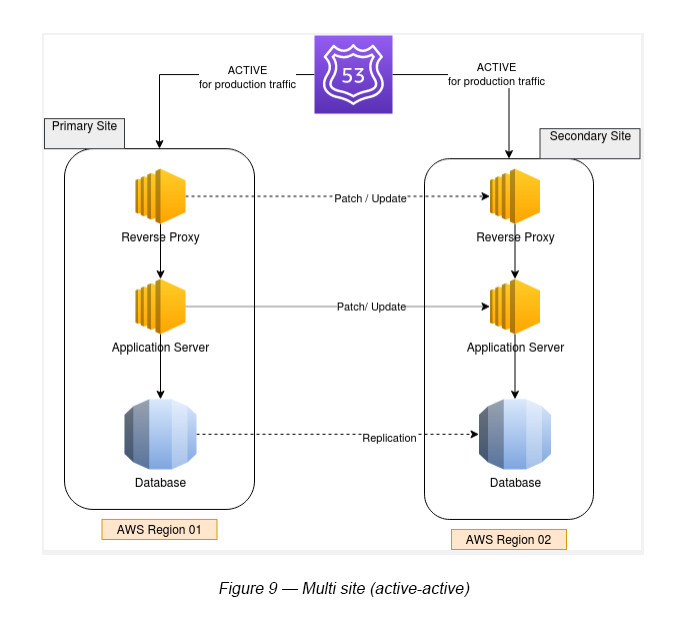
In an AWS multi-region setup, the active-active state can provide not only fail-over, but the load balancing aspect as well. We can use Route 53 to balance the load with the Weighted Routing Policy (see Figure 9).
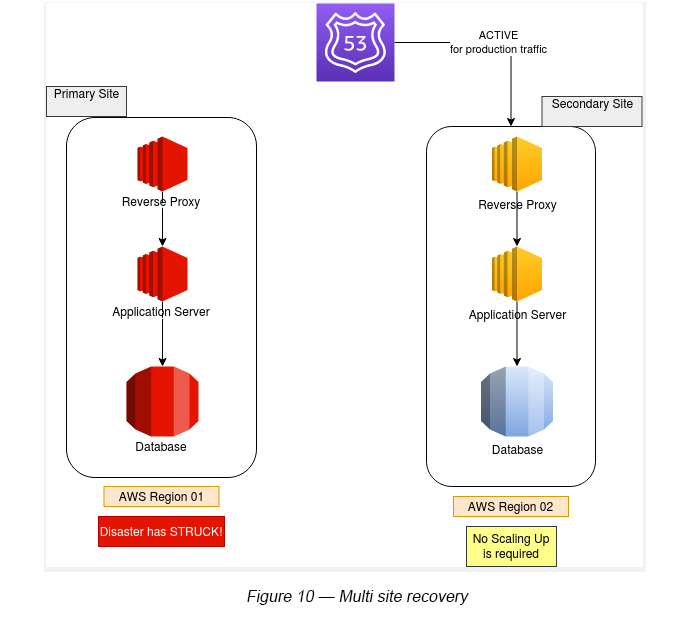
When a disaster strikes, Route 53 will route the traffic entirely to the secondary site. There is no need for any infrastructure scaling, since both the primary and secondary environments maintained a production level setup even before the disaster struck (see Figure 10).
The Comparison
Backup and Recovery: Low cost, slow in recovery (high RTO)
Pilot Light: Fairly cheap, recovery is faster than the “Backup and Recovery” method
Warm Standby: Costly, but the recovery is faster than the “Pilot Light” method
Multi Site: Very Costly (double the cost), but the recovery is faster than all other DR scenarios (almost zero recovery time/RTO)
Conclusion
Which DR scenario to adopt of the above explained ones should be purely based on the criticality and the cost that you can afford. As illustrated, the multi site approach gives you the best RTO despite its high cost factor. If cost is a major factor in your decision making process, then you can opt for one of the other three options listed.
Resources
- Using AWS for Disaster Recovery (Whitepaper) — October 2014 — AWS

Crishantha Nanayakkara
Vice President - TechnologyDeveloping a Custom Audit Trail and a Notification Service for a Workflow Based Serverless Application on AWS
READ ARTICLE
Human Emotions Recognition through Facial Expressions and Sentiment Analysis for Emotionally Aware Deep Learning Models
READ ARTICLE