AWS Aurora - Why is it better?
1.AWS Aurora — Introduction
Amazon Aurora, part of the Amazon RDS family, is a fully managed MySQL and PostgreSQL compatible, relational database engine that combines high-end commercial databases with the simplicity and cost-effectiveness of open source databases.
Amazon Aurora provides up to five times better performance than MySQL and three times better performance than PostgreSQL, without doing any programmatic changes to your existing application.
2.The RDS (MySQL / PostgreSQL) Multi-AZ Architecture
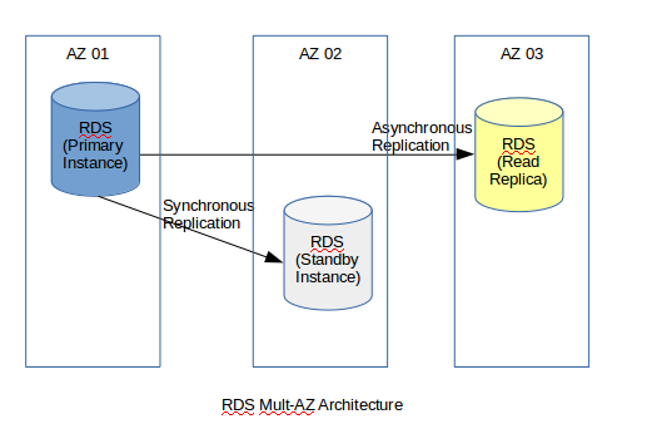
In a typical RDS (MySQL, PostgreSQL, etc.), you usually find the following Multi-AZ deployment where the primary, standby and read replicas are in different instances and the storage lies within the EBS volumes of the EC2 instance, which RDS is made of.
3.The Aurora Multi-AZ Architecture
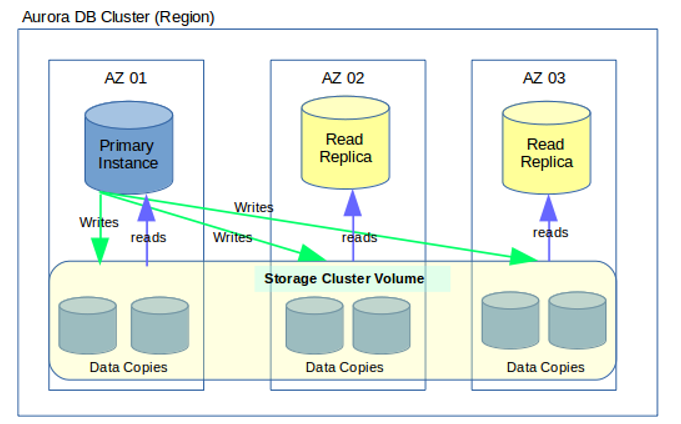
In a typical Aurora cluster, there should be a minimum of three Availability Zones within the cluster (Note: Aurora only supports regions with a minimum of three Availability Zones). The storage and the compute (EC2) are separated / independent in the Aurora cluster (See the cluster volume in the diagram where the storage exists).
Each Availability Zone maintains two copies of the storage of each RDS Aurora instance - altogether a minimum of six copies across the three Availability Zones. The master / primary compute Aurora instance writes data to the data copies in the storage cluster, and the read replicas in the other instances can read the data from the storage cluster. The storage cluster is represented as a single, logical volume to the primary instance and to Aurora Replicas in the Aurora DB cluster.
An Aurora cluster can have only one master/ primary instance. There are no standby instances in the Aurora cluster.
Since the Aurora compute instances (EC2) and the Aurora storage cluster is independent, it is quite easy to scale the storage (can scale up to 64 Tebibyte) rather than scaling within EC2 instances in a traditional RDS Multi-AZ architecture.
There can be fifteen read replicas (compared to five in a typical RDS Multi-AZ architecture). However unlike in a typical RDS cluster, the reading happens synchronously in Aurora.
4.High Availability / Fail-Over
Aurora maintains HA by having Aurora Read Replicas in the other Availability Zones. Aurora automatically fails over to an Aurora replica in case the primary DB instance becomes unavailable.
4.1.Aurora Read Replicas
Up to fifteen read replicas can be replicated across multiple Availability Zones. Since the storage cluster is represented as a single, logical volume, Aurora replicas can return the same data as query results with a minimum replica lag. This is quite different to RDS - the data is replicated to RDS Read Replicas in an asynchronous manner - where there is no need to replicate any data because the data is shared among all the instances (primary and read replicas) in the storage cluster
4.2.Primary Instance Fail-Over
If the primary instance fails, Aurora automatically fails over to a new primary instance. It does so by either creating a new primary instance or promoting a read replica. There is usually a slight interruption to the cluster during this process. The promotion of a read replica takes less time than creating a new primary instance, but if there are no read replicas in the cluster, there is no option but to create a new primary instance. Hence, AWS recommends that you should have at least one or more read replicas (with the same specification of the primary instance) to minimize the down time of the cluster.
5.Migration from other Database Engines
5.1.From RDS (MySQL/PostgreSQL) to Aurora
The data can be migrated from Amazon RDS for MySQL and Amazon RDS for PostgreSQL into Aurora. (Currently, the migration is limited to these two database engines only).
The migration can be done in two ways;
1.By creating RDS snapshots from RDS MySQL/ PostgreSQL databases and restoring them to Aurora (This is directly facilitated from the AWS Management RDS console)
2.From a standalone MySQL
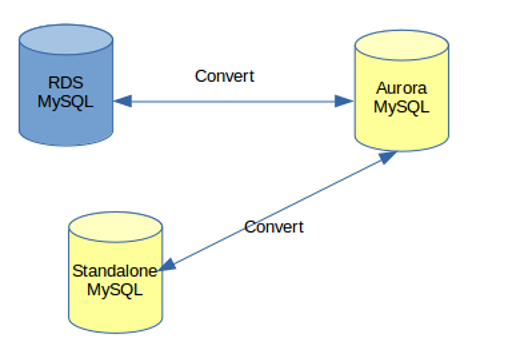
2.1.From other Database Engines
If you wish to migrate databases from databases other than MySQL or PostgreSQL, you can use AWS DMS.
6.Connection Endpoints
When you are connecting your application to an Aurora cluster, you will have to route it through a Connection Endpoint. A Connection Endpoint is represented as an Aurora specific URL that contains a host address and a port. In a nutshell, the Connection Endpoints basically abstract the underline database cluster connections allowing them to be more abstract to the application.
When you create an Aurora MySQL / PostgreSQL instance, AWS creates three endpoints at three levels by default.
1.Cluster level endpoints (Cluster endpoints)
2.Read Replica level endpoints (Reader endpoints)
3.Instance level endpoints (Instance endpoints)
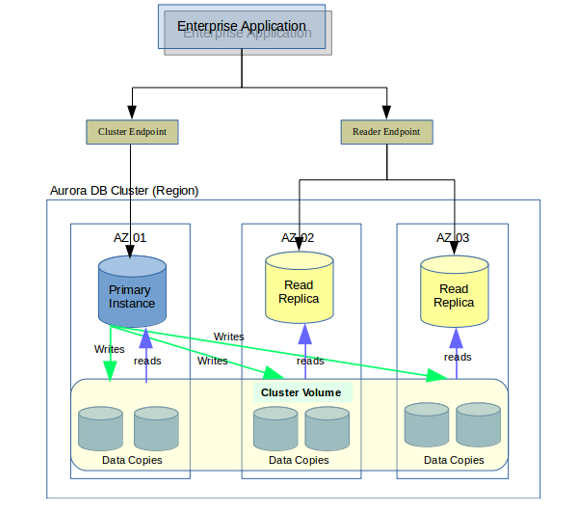
1.CLUSTER LEVEL ENDPOINTS
This connects to the current primary DB instance in the DB cluster. This is the only endpoint that can perform write operations. This is the first to be created while setting up the cluster with a single DB instance.
It provides the fail-over support for read / write connections to the DB cluster. If the current primary DB instance of a DB cluster fails, Aurora automatically routes to a read replica and promotes that instance to a primary DB instance. That will be automatically reflected to the handler and everything is done automatically. Due to this smooth transition by the handler, the client will not experience a significant downtime during the fail-over.
2.READER LEVEL ENDPOINTS
These are built-in endpoints for read replicas. If you have multiple read replicas, the reader level endpoint will balance the load among all the read replicas. If there are no read replicas available in the cluster, then the traffic will be transferred to the master instance.
3.INSTANCE LEVEL ENDPOINTS
At the instance level, one endpoint is created per instance. With the instance endpoint, you are connecting directly to the instance just like a traditional connection. Use of the instance endpoint only (without the cluster endpoint) is discouraged without a strong justification. You can use cluster endpoints along with instance endpoints for the manual load balancing of read queries.
4.CUSTOM LEVEL ENDPOINTS
In addition to the above three endpoint levels, you can create your own Custom Level Endpoints for your custom level requirements. Unlike the other three endpoint levels, you have to create these endpoints yourself.
7.Aurora — Security
AWS Aurora security is managed at many levels.
• Using IAM controls access to the Aurora DB cluster
• At the VPC level, the Aurora cluster should be created within a VPC
• Encryption is handled in-transit and at rest. When creating the cluster, there is a check box to be selected to activate the cluster encryption. However, you cannot encrypt an already created cluster. But you can restore an unencrypted cluster snapshot as an encrypted one. Once you encrypt the cluster, you cannot decrypt it.
8.Aurora — Global Databases
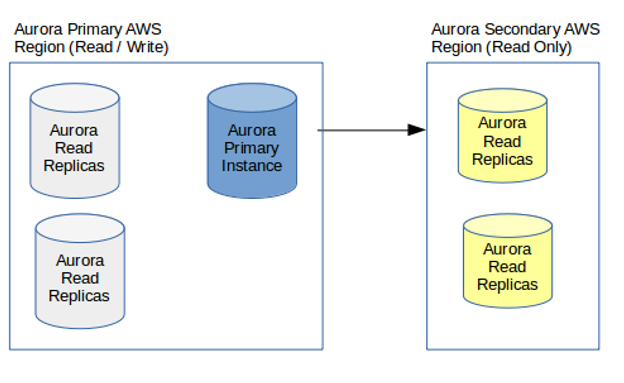
The Aurora Global Database consists of;
• One primary region — performs both read and write functions
• One secondary region — this is where the read-only replicas reside. It can be scaled out to have more replicas within the region itself
The Global Databases are useful when any application has a worldwide access. Then the secondary region can be located based on the demand it has worldwide. It can be useful in a regional fail-over as well. If for some reason, a cluster goes down, the replica can be promoted to be the primary one and can be provided with read - write capability under one minute.
The data replication happens between regions with very low latency (even under a second). A dedicated infrastructure is being used to do this task.
9.Aurora — BackTrack
Backtracking is bit similar to the Backup-Restore procedure but it does not have the same versatility that you see in the Backup-Restore process. However, if you have to backtrack to the previous state due to a mistake in the databases, it is quite an easy process. Backtracking takes less time than Backup-Restore, but the Backup-Restore process allows you to work with snapshots and can work with different clusters, whereas Backtrack confines you to a single cluster.
10.Aurora MySQL Cross Region Replication
This is different to Backtrack and does not use any global databases. This is a Aurora MySQL database replication from one region to another. You can have up to five cross-region DB clusters that are read replicas.
Aurora takes a snapshot of the source cluster and transfers the snapshot to the read replica region. This takes more time for cross region read replica created compared to Global Databases, but these regional read replicas can always be promoted to a standalone cluster at any point.
11. Aurora Serverless
Aurora Serverless is the only RDBMS serverless offering of AWS other than the NoSQL serverless offering, DynamoDB. It is compatible with both MySQL and PostgreSQL database engines.
Aurora Serverless has following benefits:
1.Simple — Removes the complexity of managing database instances and capacity. The database will automatically start up, shut down, and scale to match your application’s needs. It is a simple, cost effective option for infrequent, intermittent or unpredictable workloads.
2.Scalable — Seamlessly scale compute and memory capacity as needed with no disruption to client connections.
3.Cost Effective — Pay on a per-second basis only for the database resources you consume. You don’t pay for the database instance unless it’s actually running.
4.Highly Available — Built on distributed, fault-tolerant, self-healing Aurora storage with 6-way replication to protect against data loss.
References
1.Tebibyte (Wiki) : https://en.wikipedia.org/wiki/Tebibyte
2.Failover with Amazon Aurora PostgreSQL : https://aws.amazon.com/blogs/database/failover-with-amazon-aurora-postgresql/
3.Deep Dive into Aurora (Youtube) : https://www.youtube.com/watch?v=U42mC_iKSBg
4.Deep Dive into Aurora (Slidesshare): https://www.slideshare.net/AmazonWebServices/srv308-deep-dive-on-amazon-aurora

Crishantha Nanayakkara
Vice President - TechnologyDeveloping a Custom Audit Trail and a Notification Service for a Workflow Based Serverless Application on AWS
READ ARTICLE
Human Emotions Recognition through Facial Expressions and Sentiment Analysis for Emotionally Aware Deep Learning Models
READ ARTICLE