US-Based Global Ratings Company - Case Study
NorthBay Solutions is a recognized premier provider of Big Data outsourcing services, based in USA. NorthBay Solutions initiated its offshore consulting in Lahore, Pakistan. 1 Billion Tech, formerly Auxenta, collaborated as their second offshore consulting partner in the space of AWS Big Data consultancy.
The Challenge
The 1 Billion Tech - NorthBay team was required to develop a solution which could read files from the AWS S3 bucket where the data could be versioned and validated at record level and stored in another S3 bucket. The solution was to be automated by a JAVA driver program and AWS Data Pipeline.
It is an end-to-end proof of concept of the actual project.
HOW 1 BILLION TECH HELPED
Though it was not a direct client task from 1 Billion Tech, the ‘1 Billion Tech - NorthBay’ team took this as a training task. The proposed solution was deployed on Amazon Web services. Data transferring in the proposed solution was done by using the concept of AWS Data Pipeline. AWS S3 was used as the storage component and the computation was performed on the AWS EMR Cluster using a SparkSQL application.
THE SOLUTION
The 1 Billion Tech - NorthBay team obtained hands on experience on various components during their work on this PoC, some of which are listed below:
AWS Lambda, SNS, SQS
Triggering Lambda from a SNS Topic, then reading SQS Messages to create Data Pipelines using Lambda through JAVA SDK, by assigning proper roles.
Security (VPC, IAM, KMS)
Client and server-side encryption on S3 and Lambda functions are done using AWS KMS
Configuration of a VPC with a private and public subnet for enhancing the security. This is accomplished by using IAM Roles & Policies in order to ensure file level granularity control on S3 for various users.
Data Pipeline
Installing a Task Runner in an already running EMR so that the Data Pipeline doesn’t use up time in launching the EMR itself for running its activities. Copying files from one S3 bucket to another S3 bucket involves:
- Copy activity
- S3-data-nodes
- Scheduling
- Publish to SNS topic
This helps us control the flow of data and its processing on EMR.
AWS EMR
- Map - Reduce
Implemented Map-Reduce word counting in the EMR cluster, and saving the generated results to HDFS and S3.
- Hive
Using the EMR Hive cluster, we ran distributed queries from AWS S3 directly and placed the generated query result set in AWS S3 (from HDFS to avoid data loss after cluster termination) using AWS console, AWS CLI, and Java Code.
This approach allows us to query raw data directly from S3 in a distributed way using EMR (Hive).
SparkSQL
Deployed a SparkSQL application written in Java that reads files from S3 to data frames and is run on EMR Cluster (applied a few transformations using raw SQL queries and built-in methods).
Oozie
Created and executed a basic workflow of a map-reduce job using Oozie (implemented word count example in Python, Read files from AWS S3 and results were put back on AWS S3).
Apache Ranger
Created multiple users and assigned different policies to them for testing level access control in HDFS and table and record level access on Hive.
It helped us to create security policies on the Hadoop Ecosystem.
AWS Glue
- Data Cataloging
Created a new Glue database to store Metadata of source data and added a Crawler to extract schema and populate Metadata store.
Integration of Glue Metadata Store with other services (E.g.,: Athena, Hive).
- ETL Workflow:
Data versioning at record level.
Orchestration with AWS Glue triggers (successfully scheduled job triggers with cron expressions).
CI and CD using AWS Services
Implemented a CI/CD setup on AWS that automatically detects new code being pushed to CodeCommit and triggers a CodePipeline that users a CodeDeploy agent to deploy the latest build on specific servers (EC2 in this case).
Explored deployments including Load Balancing and Auto-Scaling groups.
CloudWatch and CloudTrail
Configured an alarm for terminating EMR instances if their CPU utilization remains less than a specific threshold (40%) for more than a specific time (30 minutes).
Architecture
Polling Based Driver
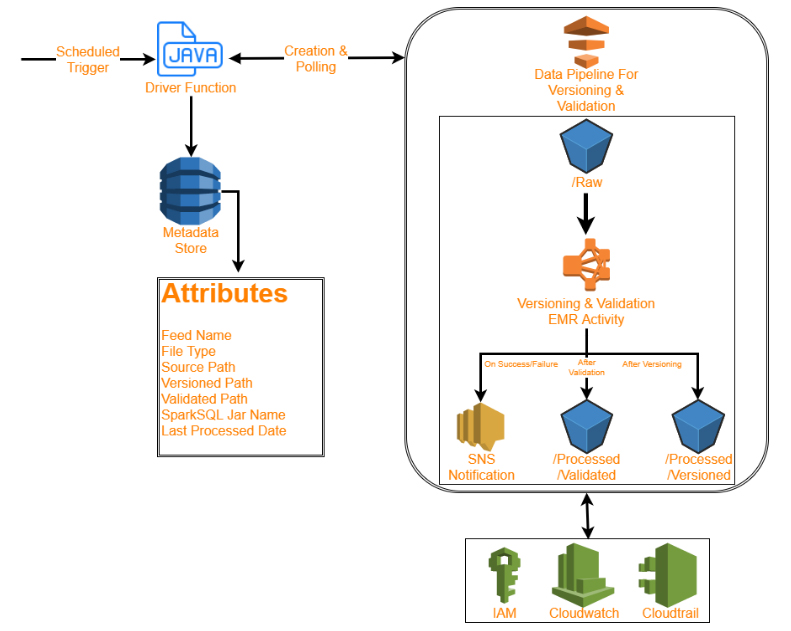
- Reads Metadata from DynamoDB
- Reads date key for each feed/filetype from S3 bucket
- Creates jobs based on this information
- Creates DataPipeline for each job
- 5 Pipelines are executed in parallel if jobs are independent
- Dependent jobs wait for pre-requisites
- Datapipeline will add a step in EMR cluster
- Poll Datapipeline status every 10 seconds
- Update last-processed-date in Dynamodb
- If finished, created next independent job
- Shutdown if all jobs were completed
Push Based Driver
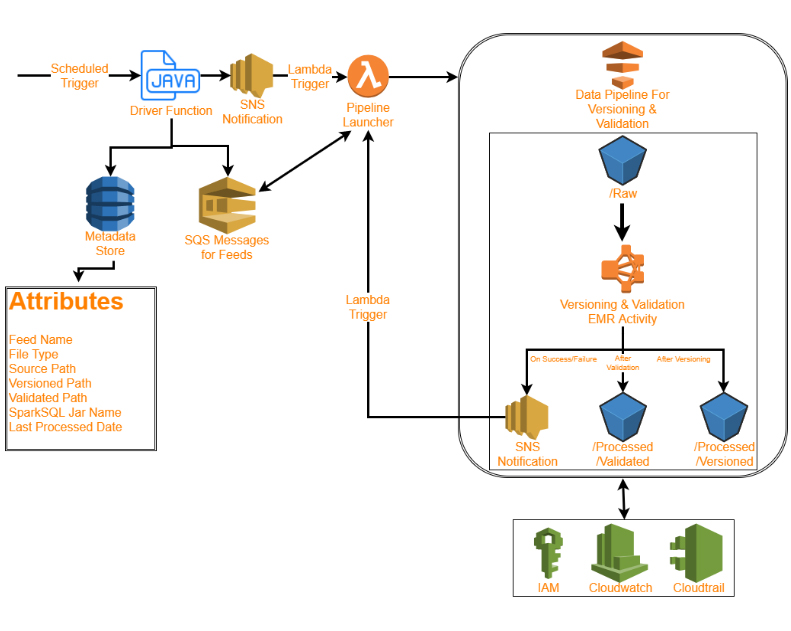
- Job Queuing on EC2/Lambda
- Reads Metadata from DynamoDB
- Reads date key for each feed/filetype from S3 bucket
- Creates SQS for jobs based on this information
- Publish to SNS after completion of job queueing
- Job triggering in Lambda
- Reads SQS and creates Data Pipeline for each job
- 5 Pipelines are executed in parallel if jobs are independent
- Dependent jobs wait for pre-requisites.
- Data Pipeline will add a step in EMR cluster that runs the same SparkSQL application for validation/versioning
- Data Pipeline published in same SNS topic upon completion
- Update last-processed-date in DynamoDB
- Deletes the SQS message
- Creates next independent job
BENEFITS TO THE CLIENT
This PoC enables the client to separate the data in the S3 bucket into validated/versioned/invalid buckets in a secure and automated way when data arrives as a batch.
The ETL job will be run once a day and presumably there will be an ETL window for it.
Once the ETL job has run successfully for a specific day, it cannot be re-run because that would bring it into an inconsistent state.